
아마존웹서비스(AWS)는 기존 서버 기반의 애플리케이션을 함수 단위로 쪼개서 실행할 수 있는 AWS 람다(Lambda) 서비스를 2014년에 출시하면서, 서버리스(Serverless) 아키텍처 시대를 열었다. 초기에는 AWS 자원의 변경이 일어나는 이벤트에 따라 간단한 동작을 수행하려는 요구 사항에 맞추어 출발했다. 하지만, 애플리케이션을 배포 및 운영해야 할 서버의 존재가 없어짐에 따라, 다양한 아이디어가 쏟아져 나왔다 아마존API 게이트웨이 서비스와 AWS가 원래 (서버 관리 필요 없이) 제공하던 아마존 S3, 다이나모DB 같은 빌딩 블록을 이용하여 서버리스 애플리케이션 모델을 구성할 수 있게 되었다.
AWS는 클라우드 기반 기계 학습과 딥 러닝 기술을 통해 다양한 사용 사례 및 요건을 해결할 수 있는 AI 서비스 제품군을 제공하고 있다. 앞서 살펴 본, 아마존 머신러닝, 딥러닝 AMI 및 딥러닝 클러스터 구성 템플릿, 클라우드에 최적화된 MXNet 같은 오픈소스 딥러닝 엔진 등이 해당된다.
AWS는 이러한 플랫폼을 이용한 인공지능에 대한 맞춤형 솔루션이 필요하지 않지만, 자신의 애플리케이션에 인공지능 기능을 활용하고자 하는 개발자라면 누구나 사용할 수 있도록 완전 관리형(Full Managed) 서비스를 제공한다. 개발자는 아마존 AI 서비스를 통해 자연어 이해(NLU), 자동 음성 인식(ASR), 비주얼 검색 및 이미지 인식, 텍스트 음성 변환(TTS), 기계 학습(ML) 기술을 이용할 수 있다. 이를 통해 개발자들은 API 호출로 스마트한 앱을 빠르게 개발하고 배포하여, 사용자 경험 향상과 비즈니스 가치를 실현할 수 있다.
■ 서버리스 AI 서비스를 위한 3종 세트
아마존 렉스(Lex)는 음성 및 텍스트를 사용해 대화형 인터페이스를 모든 애플리케이션에 구현하는 서비스다. 아마존 렉스는 음성을 텍스트로 변환하는 자동 음성 인식(ASR)과 텍스트의 의도를 이해하는 자연어 처리(NLU) 등과 같은 첨단 딥 러닝 기능을 함께 제공한다. 이를 통해 사용자 경험을 증진하고 생생한 대화형 인터페이스를 제공하는 애플리케이션을 구축할 수 있다. 현재 아마존 알렉사에 탑재되는 것과 동일한 딥 러닝 기술을 사용한 아마존 렉스는정교한 자연어 대화봇(챗봇)을 빠르고 쉽게 개발할 수 있으며, AWS 람다와 아마존 다이나모DB 등 서버리스 빌딩 블록을 통해 개발된 애플리케이션을 페이스북 채팅에도 바로 적용할 수 있다.
미국 오하이오주 공공 의료 서비스인 오하이오헬스(OhioHealth)는 “아마존 렉스를 활용하여 환자에게 더 나은 정보를 적시에 제공하고 있다. 이 혁신적인 애플리케이션은 고객에게 향상된 환경을 제공하는 데 큰 도움이 되고 있다”고 밝혔다.
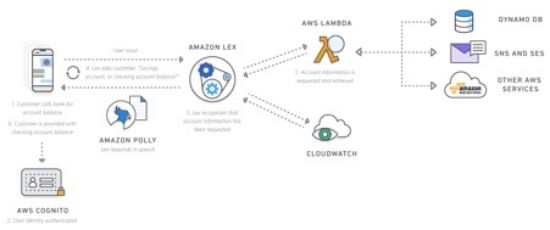
오하이오헬스에서 개발한 아마존 렉스와 기반 서버리스 의료 상담 시스템(출처: AWS 홈페이지)
아마존 리코그니션(Rekognition)은 애플리케이션에 이미지 분석을 쉽게 추가할 수 있는 서비스다. 이미지 내 피사체, 장면, 얼굴을 분석하거나, 얼굴을 검색하거나 비교할 수 있다. 매일 수십억 개가 업로드되는 프라임 포토(Prime Photos)의 이미지들을 분석하기 위해 아마존의 컴퓨터 비전 과학자들이 개발한 이 서비스는 성능이 검증되었을 뿐만 아니라 확장성까지 뛰어난 딥 러닝 기술을 기반으로 하고 있다. 이 서비스는 심층 신경망 모델을 사용하여 이미지 속의 수많은 객체와 장면을 탐지하고 태깅하며, 개발자는 아마존에서 새로운 인식 라벨과 안면 인식 기능을 지속적으로 업데이트 받을 수 있다.
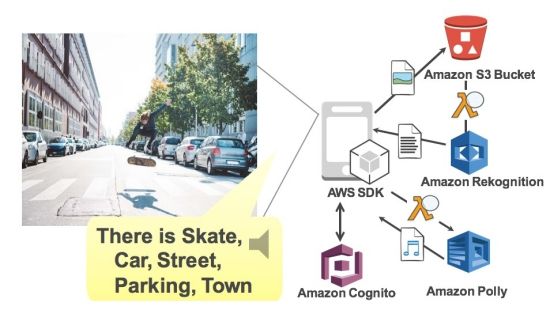
아마존 리코그니션 및 폴리를 통한 이미지 분석 및 읽어주기 앱 사용 예제(출처: AWS 홈페이지)
아마존 폴리(Polly)는 텍스트를 생생한 음성으로 변환하는 서비스로서 고급 딥러닝 기술을 사용하여 실제 사람 목소리처럼 음성을 합성한다. 24개 언어로 47가지의 실제 음성이 포함되어 있어서 여러 국가에 따라 원하는 음성을 선택하여 음성 지원 애플리케이션을 개발할 수 있다. 라이선스 규정도 간단하여 폴리의 음성 오디오를 캐싱 및 저장하여 오프라인에서 재생하거나 재배포하는 것도 가능하다. 예를 들어, ‘허클베리핀의 모험’이라는 책을 MP3 포맷의 오디오 북으로 변환할 수 있으며, 그 비용은 2.4달러 정도에 불과하다.
■ 서버리스 인공지능은 진화 중
서버리스 AI는 클라우드 애플리케이션에만 국한되지 않고 고성능 연산을 위한 플랫폼에서도 적용할 수 있다. 예를 들어, 병렬 처리를 통해 모델 선택 및 하이퍼 매개 변수 최적화를 가속화하기 위해 AWS 람다를 사용할 수 있다. AWS 람다 서비스는 분산된 병렬 처리가 가능하여, 실시간 데이터 처리와 광범위한 데이터 분석을 위한 매우 다양한 서비스로 입증되었다.
예를 들어, 맬웨어 분석 및 침입 탐지 서비스를 제공하는 보안 업체인 파이어아이는 수십 억 건의 데이터를 AWS 람다로 분석하고 있다. 대개 대용량 하둡(Hadoop) 클러스터가 필요한 맵/리듀스(Map/Reduce) 작업을 AWS 람다를 활용하여 구현하였다. AWS 람다 함수 호출을 계단식으로 호출함으로써 아마존 S3에서 데이터를 저장 처리하고, 다시 호출하는 방식을 통해 진행하였다. 기존에 아마존 EC2에서 엘라스틱서치(Elastic Search)를 사용하던 것을 AWS 람다로 옮긴 이후 똑같은 성능에도 비용을 80 % 가량 줄였다. 이는 서버리스 환경에서 대용량 데이터 처리를 수행 할 수 있는 좋은 사례이다.
AWS 람다를 MXNet과 함께 사용하여 머신 러닝 및 딥러닝에서 간편성과 유연성을 제공할 수 있는 실험 사례도 있다. 여기에서는 이미지넷(ImageNet) 우승 모델인 18 계층의 심층 신경망 네트워크를 통해 이미지 라벨을 예측하는 레지듀얼네트워크(Residual Network)을 이용하여 샘플 응용 프로그램을 만들었다.

Residual Network를 통한 손글씨 인식 예측 모델(출처: AWS 홈페이지)
AWS 람다에서 MXNet 라이브러리를 직접 컴파일하고 구축한 후, 4,495 개의 UCI Optdigits 훈련 데이터 세트 및 다른 1,125 개의 예제를 사용한 결과, EC2 인스턴스보다 5배 정도 속도가 빨라졌다. (오류율은 0.04로 같으면서도 AWS 람다 방식이 47초, 컴퓨팅 최적화된 C3.large인스턴스가 242초가 걸렸다.)
또한, 이를 글로벌 수준에서 처리하기 위한 확장성을 고려한 벤치마킹에서도 평균 지연 시간이 1.18 초로서 매우 낮았다. 라이브러리 및 코드 샘플은 mxnet-Lambda GitHub 저장소에서 살펴 볼 수 있다.
최근 인공지능 연구는 CPU/GPU 등 대용량 컴퓨팅 자원, 빠른 딥러닝 엔진 선택, 확장성 높은 클러스터 구성 등으로 인해 더욱 민첩한 결과를 얻기를 원한다. 프로세스가 더 빨라질수록 같은 시간에 모델에서 훈련할 수 있는 데이터가 많아진다. 시스템 작동이 빨라질수록 단위 시간당 더 많은 복잡성을 모델링 할 수 있다. 이를 통해 개발자는 더 빠르게 모델 정확성과 성능, 변경 사항, 최적화를 이룰 수 있어 행복하게 연구할 수 있다. 서버리스 AI로의 진화는 이러한 모든 변화에 대한 최고의 선택지가 될 수 있다.
앞서 언급한 대로 아마존 AI 플랫폼은 다양한 스펙트럼의 요구 사항을 가진 인공지능 연구자나 개발자에게 다양한 선택 옵션을 제공한다. 클라우드 기반 인공지능 연구는 물리 서버 관리, 구매, 클러스터 운영에 대한 물리적 혹은 시간적 제약을 없애고, 데이터 크기, 처리 시간, 지속적 모델 개발, 훈련에 필요한 균형 있는 대안을 제공하는 방향으로 발전하고 있다.
![[매경기고] 대세 되는 클라우드 보안 … 사업기회·인력양성 큰 場 선다](http://blog.creation.net/data/tisotry/2023/01/25070225/2023-01-25-mk-cyber-security-150x150.jpg)
![[아시아경제칼럼] 2022년, 삶을 변화시킬 클라우드 기술 트렌드 셋](http://blog.creation.net/data/tisotry/2021/12/28114229/20211228_02100127000002-150x150.png)
![[아시아경제 칼럼] 클라우드가 지속가능 경영을 앞당긴다](http://blog.creation.net/data/tisotry/2021/11/02133833/20211102_02100127000002-150x150.png)
![[아시아경제 칼럼] 클라우드가 의료산업을 재창조하고 있다](http://blog.creation.net/data/tisotry/2021/08/31121436/20210831_02100127000002-150x150.png)
※ Disclaimer- 본 글은 개인적인 의견일 뿐 제가 재직했거나 하고 있는 기업의 공식 입장을 대변하거나 그 의견을 반영하는 것이 아닙니다. 사실 확인 및 개인 투자의 판단에 대해서는 독자 개인의 책임에 있으며, 상업적 활용 및 뉴스 매체의 인용 역시 금지함을 양해해 주시기 바랍니다. 본 채널은 광고를 비롯 어떠한 수익도 창출하지 않습니다. (The opinions expressed here are my own and do not necessarily represent those of current or past employers. Please note that you are solely responsible for your judgment on checking facts for your investments and prohibit your citations as commercial content or news sources. This channel does not monetize via any advertising.)