
4편에서는 사전 학습된 Inception v3 모델을 사용하여, 이미지 내 분류를 검색하는 것이 얼마나 쉬운지 확인했습니다. 이 글에서는 두 개의 유명한 합성곱 신경망(Convolutional neural network, CNN)인 VGG19와 ResNet-152을 사용해 보고, Inception v3 모델과 비교해 보겠습니다.
CNN이라는 어려운 단어가 나왔지만, 과정은 크게 다르지 않습니다. 레이어를 더 많이 늘린 것입니다.
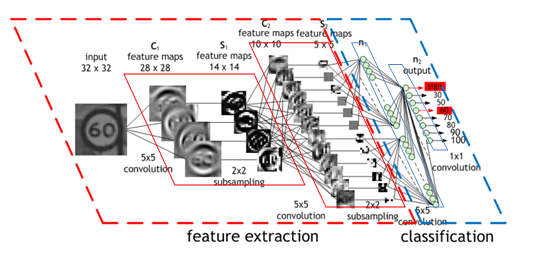
Architecture of a CNN (Source: Nvidia)
VGG16
2014 년에 발표된 VGG16은 16 개의 레이어로 구성된 모델입니다 (연구 논문). 객체 분류에서 7.4 %의 오류율을 달성하여 2014 년 ImageNet Challenge에서 우승했습니다.
ResNet-152
2015 년에 발표된 ResNet-152는 152 개의 레이어 (연구 논문)로 구성된 모델입니다. 이미지 내 객체 탐지에 대한 오류율 3.57 %를 달성함으로써 2015 ImageNet Challenge에서 우승했습니다. 이건 진짜 놀라운 결과인데, 인간이 대체적으로 5 %의 오류율을 가지는데 (100개를 보면 5개를 긴가민가하게 생각하는) 사람 보다 더 똑똑하다고 볼 수 있겠죠.
모델 다운로드 하기
MXNet zoo를 다시 방문 할 시간입니다! Inception v3와 마찬가지로 모델 정의와 매개 변수를 다운로드해야합니다. 세 모델 모두 동일한 카테고리에 대해 교육을 받았으므로 synset.txt 파일을 다시 사용할 수 있습니다.
$ wget http://data.dmlc.ml/models/imagenet/vgg/vgg16-symbol.json $ wget http://data.dmlc.ml/models/imagenet/vgg/vgg16-0000.params $ wget http://data.dmlc.ml/models/imagenet/resnet/152-layers/resnet-152-symbol.json $ wget http://data.dmlc.ml/models/imagenet/resnet/152-layers/resnet-152-0000.params
모델 로딩하기
세 가지 모델은 224 X 224의 전형적인 이미지 크기의 ImageNet 데이터 셋을 기반으로 학습하기 때문에 우리가 이전에 사용한 코드를 재사용 할 수 있습니다.
우리가 바꾸어야하는 것은 모델 이름입니다 : loadModel()과 init() 함수에 매개 변수를 추가합니다.
def loadModel(modelname):
sym, arg_params, aux_params = mx.model.load_checkpoint(modelname, 0)
mod = mx.mod.Module(symbol=sym)
mod.bind(for_training=False, data_shapes=[('data', (1,3,224,224))])
mod.set_params(arg_params, aux_params)
return mod
def init(modelname):
model = loadModel(modelname)
cats = loadCategories()
return model, cats
모델별 예측 비교하기
이전에 사용한 샘플 이미지를 기반으로 이번 두 가지 모델을 비교해 보겠습니다.

*** VGG16 [(0.58786136, 'n03272010 electric guitar'), (0.29260877, 'n04296562 stage'), (0.013744719, 'n04487394 trombone'), (0.013494448, 'n04141076 sax, saxophone'), (0.00988709, 'n02231487 walking stick, walkingstick, stick insect')]
상위 2개 카테고리는 잘 맞는데, 나머지 3개는 잘못되었습니다. 마이크 받침대의 수직 모양에서 혼란스러워하네요.
*** ResNet-152 [(0.91063803, 'n04296562 stage'), (0.039011702, 'n03272010 electric guitar'), (0.031426914, 'n03759954 microphone, mike'), (0.011822623, 'n04286575 spotlight, spot'), (0.0020199812, 'n02676566 acoustic guitar')]
상위 카테고리에서 매우 높습니다. 나머지 4 개 모두 의미가 있습니다.
*** Inception v3 [(0.58039135, 'n03272010 electric guitar'), (0.27168664, 'n04296562 stage'), (0.090769522, 'n04456115 torch'), (0.023762707, 'n04286575 spotlight, spot'), (0.0081428187, 'n03250847 drumstick')]
상위 2 개 카테고리의 VGG16과 매우 유사한 결과. 나머지 세 개는 역시 잘 모르겠네요.
다른 사진으로 해볼까요?

*** VGG16 [(0.96909302, 'n04536866 violin, fiddle'), (0.026661994, 'n02992211 cello, violoncello'), (0.0017284016, 'n02879718 bow'), (0.00056815811, 'n04517823 vacuum, vacuum cleaner'), (0.00024804732, 'n04090263 rifle')] *** ResNet-152 [(0.96826887, 'n04536866 violin, fiddle'), (0.028052919, 'n02992211 cello, violoncello'), (0.0008367821, 'n02676566 acoustic guitar'), (0.00070532493, 'n02787622 banjo'), (0.00039021231, 'n02879718 bow')] *** Inception v3 [(0.82023674, 'n04536866 violin, fiddle'), (0.15483995, 'n02992211 cello, violoncello'), (0.0044540241, 'n02676566 acoustic guitar'), (0.0020963412, 'n02879718 bow'), (0.0015099624, 'n03447721 gong, tam-tam')]
세 가지 모델 모두 상위 카테고리에서 매우 높은 점수를 받았습니다. 바이올린의 모양이 신경망에 대해 매우 모호한 패턴이라고 가정 할 수 있습니다.
몇 가지 샘플에서 사용 여부를 결정해서는 안됩니다. 사전 학습된 모델을 찾고 있다면 반드시 학습 데이터 셋을 잘 살펴보고, 자신의 데이터에 대한 테스트를 실행하고 사용할지 여부를 정해야합니다!
기술적 성능 비교
위의 연구 논문에서 많은 모델의 성능에 대한 벤치 마크 결과를 보실 수 있습니다. 개발자의 경우, 가장 중요한 두 가지 요인은 다음과 같습니다.
- 모델에 필요한 메모리 양은 얼마인가?
- 얼마나 빨리 예측 가능한가?
첫 번째 질문에 답하기 위해 우리는 매개 변수 파일의 크기를 보고 추측을 할 수 있습니다.
- VGG16: 528MB (about 140 million parameters)
- ResNet-152: 230MB (about 60 million parameters)
- Inception v3: 43MB (about 25 million parameters)
보시다시피 더 적은 매개 변수로 더 많은 레이어로 심층 네트워크를 사용하는 것입니다. 이것은 교육 시간 단축(네트워크가 매개 변수를 덜 학습하므로)과 메모리 사용량 감소라는 두 가지 이점이 있습니다.
두 번째 질문은 조금 복잡해서 배치 크기와 같은 다양한 매개 변수에 따라 달라집니다. 예측 호출 및 실행 시간에 중점을 두고 예제를 다시 실행 해 봅시다.
t1 = time.time()
model.forward(Batch([array]))
t2 = time.time()
t = 1000*(t2-t1)
print("Predicted in %2.2f millisecond" % t)
결과는 다음과 같습니다. (몇 번 호출한 뒤 평균값입니다.)
*** VGG16 Predicted in 0.30 millisecond *** ResNet-152 Predicted in 0.90 millisecond *** Inception v3 Predicted in 0.40 millisecond
자! 이제 요약을 해보죠. ResNet-152는 세 가지 네트워크 중에서 가장 우수한 정확도를 가졌지만, 2-3 배 더 느립니다.
VGG16은 레이어 수가 적기 때문에 가장 빠릅니다. 그러나, 높은 메모리 사용과 최악의 정확도를 가지고 있습니다.
Inception v3은 더 빠른 정확성과 가장 보수적인 메모리 사용을 제공하는 동시에 거의 빠릅니다. 이 마지막 점은 실시간 분석과 같은 제한된 환경에서는 좋은 후보가 됩니다. 이에 대한 자세한 부분은 마지막 6편에서 다뤄 보겠습니다.
다음 글: MXNet 시작하기 (6) – Raspberry Pi에서 실시간 객체 분석 하기
연재 순서
- MXNet 시작하기 (1) – NDArrays API
- MXNet 시작하기 (2) – Symbol API
- MXNet 시작하기 (3) – Module API
- MXNet 시작하기 (4) – 이미지 분류를 위한 학습 모델 사용하기 (Inception v3)
- MXNet 시작하기 (5) – VGG16 및 ResNet-152 학습 모델 사용하기
- MXNet 시작하기 (6) – Raspberry Pi에서 실시간 객체 분석 하기
코드 전체 보기



※ Disclaimer- 본 글은 개인적인 의견일 뿐 제가 재직했거나 하고 있는 기업의 공식 입장을 대변하거나 그 의견을 반영하는 것이 아닙니다. 사실 확인 및 개인 투자의 판단에 대해서는 독자 개인의 책임에 있으며, 상업적 활용 및 뉴스 매체의 인용 역시 금지함을 양해해 주시기 바랍니다. 본 채널은 광고를 비롯 어떠한 수익도 창출하지 않습니다. (The opinions expressed here are my own and do not necessarily represent those of current or past employers. Please note that you are solely responsible for your judgment on checking facts for your investments and prohibit your citations as commercial content or news sources. This channel does not monetize via any advertising.)