
1편에서는 몇 가지 MXNet 기본 사항을 살펴보고, NDArray API에 대해 알아보았습니다 (요약하면, NDArrays는 데이터, 매개 변수 등을 저장하는 장소입니다.) 이제 MXNet이 계산 단계를 정의하는 방법을 살펴 보겠습니다.
계산 단계? 코드를 말하는 건가요?
좋은 질문이네요. 우리 모두가 “프로그램 = 데이터 구조 + 코드”라고 배웠으니까요. NDArrays가 데이터 구조라면 이제 코드를 추가하면 됩니다.
일반적으로 모든 계산 단계를 명시적으로 정의하고 데이터에서 순차적으로 실행해야 합니다. 이를 “명령형 프로그래밍(Imperatitive Programming)“이라고 하며 Fortran, Pascal, C, C ++ 등이 작동하는 방식입니다.
그러나, 신경망(Neural Nework)은 본질적으로 병렬 컴퓨팅을 지향합니다. 주어진 레이어 내부에서 모든 산출물을 동시에 계산할 수 있어야 합니다. 독립적인 레이어도 병렬로 실행될 수 있습니다. 따라서, 좋은 성능을 얻으려면 멀티 스레딩이나 비슷한 것을 사용하여 병렬 처리를 구현해야 합니다. 보통 어떻게 작동할지 가늠이 되실 텐데요. 코드를 잘 짰다하더라도 데이터 크기나 네트워크 레이아웃이 계속 바뀌면 얼마나 재사용성이 클 수가 없겠죠.
다행히 대안이 있습니다.

데이터 흐름 프로그래밍 (Dataflow programming)
“데이터 흐름 프로그래밍”은 데이터를 그래프로 통해 흐르는 병렬 계산을 정의하는 방법입니다. 그래프는 동작 순서, 즉 순차적으로 실행할지 또는 병렬로 실행 가능할지 여부를 결정합니다. 각 동작은 블랙 박스입니다. 실제 동작을 지정하지 않고 입력과 출력만 정의합니다.
이것은 컴퓨팅에 대한 횡설수설(?)로 들릴지 모르지만, 사실 이러한 모델이 신경망을 정의하는 데 정확히 필요합니다. 입력 데이터를 “레이어”라고 부르는 동작 순서에 따라 흐리게 하는데, 이들 레이어는 병렬적으로 실행하는 많은 명령을 가집니다.
이야기는 그만하고 실제 사례를 살펴보죠. E를 (A * B) + (C * D)로 정의하는 방법입니다.
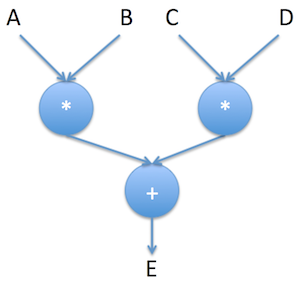
E = (A * B) + (C * D)
여기에서 A, B, C, D가 무엇인지는 큰 관계가 없습니다. 단지 기호(Symbol)일 뿐입니다.
입력 값 (정수, 벡터, 행렬 등)에 관계없이 위의 그래프는 “+” 및 “*” 연산을 정의한 경우, 출력 값을 계산하는 방식을 알려줍니다.
이 그래프는 (A * B)와 (C * D)가 동시에 병렬로 계산할 수 있다는 사실을 알 수 있습니다. 물론, MXNet은 이러한 정보를 최적화 목적으로 사용합니다.
Symbol API
이제 이를 왜 기호라고 부르는 지 자세히 알아보고자, 위의 예제를 코딩 할 수 있는지 살펴 보겠습니다.
>>> import mxnet as mx
>>> a = mx.symbol.Variable('A')
>>> b = mx.symbol.Variable('B')
>>> c = mx.symbol.Variable('C')
>>> d = mx.symbol.Variable('D')
>>> e = (a*b)+(c*d)
어떤가요? 이러한 방식으로 a, b, c, d가 무엇인지 모른 채로 결과를 e에 지정할 수 있습니다. 좀 더 살펴 볼까요?
>>> (a,b,c,d) (<Symbol A>, <Symbol B>, <Symbol C>, <Symbol D>) >>> e <Symbol _plus1> >>> type(e) <class 'mxnet.symbol.Symbol'>
a, b, c, d는 명시적으로 선언 한 기호입니다. 근데 e는 다르죠. 기호이긴 하지만 ‘+’연산의 결과입니다. e에 대해 더 자세히 알아 보죠.
>>> e.list_arguments() ['A', 'B', 'C', 'D'] >>> e.list_outputs() ['_plus1_output'] >>> e.get_internals().list_outputs() ['A', 'B', '_mul0_output', 'C', 'D', '_mul1_output', '_plus1_output']
위의 코드를 통해 알 수 있는 것은…
- e는 변수 a, b, c, d에 의존하며,
- e를 계산하는 연산은 이들의 합계이며,
- e는 실제로 (a * b) + (c * d)입니다.
우리는 물론 ‘+’및 ‘*’기호 보다 훨씬 많은 것을 할 수 있습니다. NDArrays와 마찬가지로 다양한 연산을 정의할 수 있구요. 자세한 것은 API 세부 정보를 살펴 보세요.
이제 연산 단계를 정의하는 방법을 배웠으니, 실제 데이터에 적용하는 방법을 살펴 보겠습니다.
NDArrays 와 Symbols 바인딩 하기
NDArrays에 저장된 데이터에 기호(Symbols)로 정의한 연산 단계를 적용하려면 ‘바인딩(Binding)’이라고 하는 연산, 즉 그래프의 각 입력 변수에 NDArray를 할당해야합니다.
앞에서 본 사례를 계속 해서 ‘A’를 1, B를 2, C를 3으로, D를 4로 설정합니다. 그런 다음 하나의 정수를 포함하는 4 개의 NDArrays를 생성합니다.
>>> import numpy as np >>> a_data = mx.nd.array([1], dtype=np.int32) >>> b_data = mx.nd.array([2], dtype=np.int32) >>> c_data = mx.nd.array([3], dtype=np.int32) >>> d_data = mx.nd.array([4], dtype=np.int32
다음으로 각 NDArray를 해당 Symbol에 바인딩합니다. 연산을 실행을 수행할 컨텍스트 (CPU 또는 GPU)를 선택해야 한다는 점 알아두세요.
>>> executor=e.bind(mx.cpu(), {'A':a_data, 'B':b_data, 'C':c_data, 'D':d_data})
>>> executor
<mxnet.executor.Executor object at 0x10da6ec90>
c, d는 명시적으로 선언 한 기호입니다. 근데 e는 다르죠. 기호이긴 하지만 ‘+’연산의 결과입니다. e에 대해 더 자세히 알아 보죠.
이제 결과를 얻기 위해 입력 데이터가 그래프를 따라 진행시키기 위해 forward () 함수를 사용할 차례입니다. 그래프에 여러 개의 출력이 있을 수 있으므로, NDArrays 배열을 반환합니다. 여기서 우리는 (1 * 2) + (3 * 4)와 동등한 값인 ’14’값을 갖는 단일 출력을 갖습니다.
>>> e_data = executor.forward() >>> e_data [<NDArray 1 @cpu(0)>] >>> e_data[0] <NDArray 1 @cpu(0)> >>> e_data[0].asnumpy() array([14], dtype=int32)
0과 1 사이의 무작위 부동 소수점(random floats)으로 채워지는 4개의 1000 x 1000 행렬에 같은 그래프를 적용 해 봅시다. 우리가 할일은 새로운 입력 데이터를 정의하는 것 뿐이구요. 바인딩과 계산 방식은 동일합니다.
>>> a_data = mx.nd.uniform(low=0, high=1, shape=(1000,1000)) >>> b_data = mx.nd.uniform(low=0, high=1, shape=(1000,1000)) >>> c_data = mx.nd.uniform(low=0, high=1, shape=(1000,1000)) >>> d_data = mx.nd.uniform(low=0, high=1, shape=(1000,1000))
>>> executor=e.bind(mx.cpu(), {'A':a_data, 'B':b_data, 'C':c_data, 'D':d_data})
>>> e_data = executor.forward()
>>> e_data [<NDArray 1000x1000 @cpu(0)>] >>> e_data[0] <NDArray 1000x1000 @cpu(0)> >>> e_data[0].asnumpy() array([[ 0.89252722, 0.46442914, 0.44864511, ..., 0.08874825, 0.83029556, 1.15613985], [ 0.10265817, 0.22077513, 0.36850023, ..., 0.36564362, 0.98767519, 0.57575727], [ 0.24852338, 0.6468209 , 0.25207704, ..., 1.48333383, 0.1183901 , 0.70523977], ..., [ 0.85037285, 0.21420079, 1.21267629, ..., 0.35427764, 0.43418071, 1.12958288], [ 0.14908466, 0.03095067, 0.19960476, ..., 1.13549757, 0.22000578, 0.16202438], [ 0.47174677, 0.19318949, 0.05837669, ..., 0.06060726, 1.01848066, 0.48173574]], dtype=float32)
멋지죠? 이러한 데이터와 연산 상호 간의 명확한 분리를 통해 우리는 두 가지 장점을 모두 얻을 수 있습니다.
- 데이터는 우리가 잘 알고있는 명령형 프로그래밍 모델을 사용하여 가져와 준비합니다. 우리는이 과정에서 외부 라이브러리를 사용할 수도 있습니다. (옛날 코드도 상관 없어요!)
- 연산은 심볼릭 프로그래밍 모델을 사용하여 수행됩니다. 이는 MXNet에서 코드와 데이터를 분리 할뿐만 아니라 그래프 최적화된 병렬 연산을 가능하게 합니다.
오늘은 여기까지 살펴 보고, 다음에는 신경망에서 모델 학습을 하기 전에 마지막으로 Module API를 살펴볼 것입니다.
다음 글: MXNet 시작하기 (3) – Module API
연재 순서
- MXNet 시작하기 (1) – NDArrays API
- MXNet 시작하기 (2) – Symbol API
- MXNet 시작하기 (3) – Module API
- MXNet 시작하기 (4) – 이미지 분류를 위한 학습 모델 사용하기 (Inception v3)
- MXNet 시작하기 (5) – VGG16 및 ResNet-152 학습 모델 사용하기
- MXNet 시작하기 (6) – Raspberry Pi에서 실시간 객체 분석 하기



※ Disclaimer- 본 글은 개인적인 의견일 뿐 제가 재직했거나 하고 있는 기업의 공식 입장을 대변하거나 그 의견을 반영하는 것이 아닙니다. 사실 확인 및 개인 투자의 판단에 대해서는 독자 개인의 책임에 있으며, 상업적 활용 및 뉴스 매체의 인용 역시 금지함을 양해해 주시기 바랍니다. 본 채널은 광고를 비롯 어떠한 수익도 창출하지 않습니다. (The opinions expressed here are my own and do not necessarily represent those of current or past employers. Please note that you are solely responsible for your judgment on checking facts for your investments and prohibit your citations as commercial content or news sources. This channel does not monetize via any advertising.)